|
VorwortIm folgenden wird die grundsätzliche Vorgehensweise bei einer Mpeg-Kodierung erläutert. Bitte lesen Sie den Haftungsauschluss im Impressum. GeschichtlichesBei Mpeg handelt es sich um eine Gruppe aus Entwicklern, Ingenieuren und Mathematikern, die sich 1988 zur Moving
Pictures Expert Group mit dem offiziellen Namen ISO/IEC JTC1 SC29 WG11 zusammenschlossen. Ziel dieser Gruppe war es,
ein Komprimierungssystem für Daten zu erfinden, um Speicherplatz zu sparen und diese damit internettauglich zu machen,
denn bei Mpeg handelt es sich auch um ein internetorientiertes Unternehmen. Was der Name dieser Gruppe nicht in sich birgt
(Moving Pictures = Bewegende Bilder = Film) ist, dass dieses Komprimierungsverfahren zunächst nicht bei Filmen angewandt
wurde, sondern bei Audiodaten. Als erstes Produkt der Mpeg1 Familie kam nämlich wider erwarten 1989 das MP3 Format auf den
Markt, das bis heute noch Spitzenreiter in der Audiokomprimierung ist. Das für die Video CD taugliche Mpeg1 Format kam erst
1993 auf den Markt. Es besteht heute aus 5 Teilen, wovon sich alle als Standard durchgesetzt haben. Als preisgekröntes
Komprimierungsformat (Emmy Award) wurde es ab 1996 zu Mpeg2 weiterentwickelt. Auch dieses Format gewann wie sein Vorgänger
den Emmy Award und wurde bis Mitte 2000 weiterentwickelt. Das Mpeg2 Format besteht nun aus neun Teilen, von denen sich drei
als Standard durchgesetzt haben. Das wohl zur Zeit fortschrittlichste und auch aktuellste Format der Moving Pictures Expert
Group ist das 1999 auf den Markt gebrachte (und standardisierte) Mpeg4 Format. Dieses Format hat heutzutage die stärksten
Komprimierungseigenschaften in nahezu DVD Qualität. Leider konnte es bislang das auf DVD's übliche Mpeg2 Format noch nicht
ablösen, da bis vor kurzem kein DVD Spieler Mpeg 4 lesefühig war. Es gibt zwar mittlerweile DVD Spieler, die Mpeg4
tauglich sind, jedoch ist das Mpeg2 Format immer noch DVD Standard, da Die Mpeg2 Spieler sehr stark verbreitet sind und kaum einer
extra wegen Mpeg4 einen neuen DVD Spieler kaufen will. In Zukunft wird sich das Videoformat für DVD´s ändern.
BlueRay und Konsorten sind im Gespräch und sollen künftig bis zu 40 GB Speicherkapazität bieten. Der KodierungsvorgangWas Mpeg macht und istUm einen Film in Mpeg zu kodieren werden verschiedene Schritte benötigt, um die vorhandenen Bilddaten zu komprimieren.
Das beginnt bereits beim Farbraum. Nachdem das menschliche Auge weniger Chrominanzwerte (Farbwerte) als Luminanzwerte
(Helligkeitswerte) unterscheiden kann, werden die Bildinformationen in einen anderen Farbraum übergeben. Weiterhin wird
mit der Trägheit des menschlichen Auges gearbeitet, um weiteren Speicherplatz zu sparen. Durch geschickte Voraussagungen
und Abschätzungen lassen sich dann noch einmal einige MB einsparen. YCbCr - Ein neuer FarbraumDer RGB Farbraum ist aufgrund seines hohen Speicherbedarfs und seiner geringen Wahrnehmbarkeit überflüssig. Deshalb wird
dieser Farbraum in einen für das menschliche Auge angepassten Farbraum (YCbCr entspricht YUV) transportiert. Das erfolgt
dahingegen, dass im YUV Farbraum ein Teil Luminanzwerte und zwei Teile Chrominanzwerte tragen. Diese Teile werden dann, wie bei
RGB auch, mit 8 Bit Farbtiefe abgespeichert (äquivalent zu Bildauflösungen). Normalerweise würde das zur gleichen
Farbtiefe wie im RGB Format führen (auch 3 Teile). Deshalb werden die beiden Farbanteile nur mit halber Auflösung
abgespeichert, was der Name YUV 4:2:2 bereits in sich birgt (bei Jpeg-Bildern ist das 4:1:1). Das spart nun rund ein Drittel
des eigentlichen Speicherbedarfs.
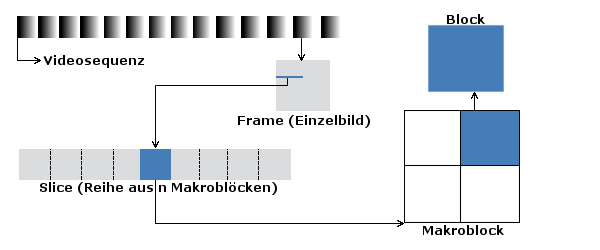
Die eigentliche Videosequenz wird in die verschiedenen Einzelbilder zerlegt. Danach werden die Zeilen (Slices), die aus diversen Makroblöcken bestehen, in 8x8 Pixel Blöcke unterteilt. Wie diese Blöcke durch geschickte Vektordarstellungen und "Voraussagungen" in ihrem Speicherbedarf reduziert werden, folgt. ↑ Nach obenDPCM - Differenzpulsecodemodulation und Motion Compensation SearchDiese, zugegebenermaßen kompliziert klingenden Begriffe sind weitere Methoden, um den Speicherbedarf eines Filmes zu
verringern. Dazu erst einmal ein Beispiel:
Diese Bilder werden in einer geschickten und beliebigen Reihenfolge zu einer sogenannten GOP (Group of pictures) zusammengestellt. Ein Beispiel für eine solche Zusammenstellung ist im folgenden Bild zu sehen: 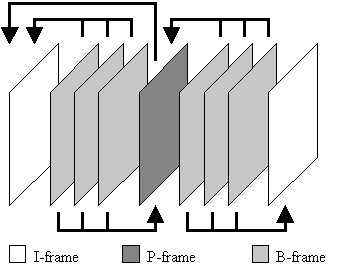
Diese Bilderfolge ist allerdings nicht mehr komperativ mit der ursprünglichen Bildsequenz. Die Bilder in der GOP werden nicht so zusammengestellt wie sie abgespielt werden, sondern in einer logischen Reihenfolge. Das muss auch so sein, weil ein B-Frame schließlich ein vorangegangenes als auch ein folgendes Bild benötigt (mit Ausnahme der Referenzierung in eine Richtung). Damit man nun nicht nur große Bewegungszustände mit sogenannten Referenzvektoren (=Verschiebungsvektoren, keine Ortsvektoren!) beschreiben kann, werden die Luminanzanteile in Makroblöcke und die Chrominanzwerte in Blöcke aufgeteilt. Diese Makroblöcke werden dann mit den vorangegangenen und folgenden Bildern nach bester Übereinstimmung verglichen. 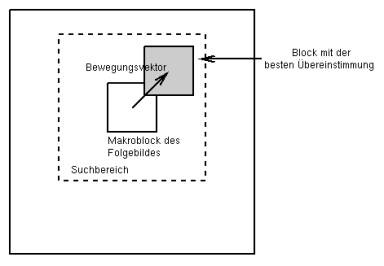
Wird nun ein Block mit einer sehr großen Übereinstimmung gefunden, wird der Fehlerterm (die Differenz) und der Referenzvektor kodiert. Andernfalls wird der Makroblock intrakodiert abgespeichert. Die Methode zum Suchen und das Festlegen des Suchbereiches und dessen Genauigkeit bleibt dem Konvertierer überlassen. In der Regel werden aber entweder die sog. Teleskopsuche oder die logarithmische Suche verwendet. Die bereits gespeicherten Referenzvektoren werden dann wieder nach DPCM kodiert, indem man eben den Fehlerterm (Differenz zu den Vektoren der vorangegangenen Makroblöcke) und eben der neue Referenzvektor gespeichert werden. ↑ Nach obenDCT - Die Diskrete KosinustransformationBei der diskreten Kosinustransformation werden die von der DPCM in Binärdaten umgewandelten Filmdaten weiter verarbeitet. Hierbei wird mit 8x8 Pixel Blöcken gearbeitet und folgende "Hauptformel" angewandt: 
Das N in der Formel entspricht der Anzahl der Pixel eines Blocks (vertikal und horizontal). Das heißt, wenn ein Block mit
8x8 Pixel konvertiert werden soll, ist N=8. Diese Matrix aus 8x8 Werten (=64) wird aus dem zeitlich abhängigen Bereich
in einen Frequenzbereich transformiert. Diese Transformation lehnt stark an die Fourier- oder Leplacetransformation an. Der Wert
gij ist der Farbwert in der Matrix an der Stelle (i,j), wobei i dem Spaltenindex und j dem Spaltenzahl zugeordnet wird. Guv ist
demnach der neue Wert in der transformierten Matrix in der u-ten Spalte und der v-ten Zeile. An der oberen, linken Stelle der
Matrix (Stelle (0,0)) befindet sich der DC-Wert. Da sich benachbarte Blöcke kaum voneinander unterscheiden, werden die DC-Werte
nur als Differenz zu benachbarten Blöcken kodiert. Alle anderen Werte werden mit steigender Zeilen- und Spaltenzahl
hochfrequenter und repräsentieren AC-Werte (wie in der Elektrotechnik). Der DC-Wert wird auch als Gleichanteil bezeichnet.
Desweiteren wird mit der Blöckgröße, mit der konvertiert wird, die Genauigkeit der Umwandlung bezeichnet. Diese
wird entweder vom Benutzer oder vom Programm festgelegt. Die QuantisierungDie von der DCT erhaltenen Matrizen werden nun noch quantisiert. Das hat den Hintergrund, dass die bisher gespeicherten Werte
immer noch ihren Fokus auf den hochfrequenten Filmdaten haben. Die Quantisierung ist ein rein rechnerisches Verfahren, bei
dem jeder Matrixwert aus der DCT mit seinem dazugehörigen Wert in der sogenannten Quantisierungstabelle dividiert wird.
Diese Quantisierungstabelle und die darin enthaltenen Divisoren werden für die verschiedenen Filmarten optimiert. So
haben ein "natürlicher" Film und animierter (Zeichentrick-) Film unterschiedliche Quantisierungsmatrizen. 
Bei der Intraquantisierung spricht man von einem schmalen Nullband, da die meisten Werte immer noch über Null liegen. Im Gegensatz dazu bekommt man bei der Interquantisierung ein breites Nullband, da die meisten Werte zu Null reduziert werden. Zuletzt ist noch zu erwähnen, dass der Wert der Quantisierungstabelle an der Stelle (0,0), also der DC-Wert immer 8 sein muss. ↑ Nach obenDie RLE-Kodierung (Run-Length-Encoding)Nachdem die Bilddaten nun effizient komprimiert wurden, müßen nun noch eine neue Filmsequenz mit den neuen Bilddaten erstellt werden. Das beginnt mit der sog. Serialisierung der Bilddaten, dass heißt konkret in diesem Fall, dass die quantisierten DCT-Werte nacheinander, ihrem Wert hierarchisch aufsteigend, gereiht werden. Dies geschieht, nachdem die Beträge von der jeweiligen Position abhängig sind, im Zick-Zack Verfahren: 
Nachdem die Werte aneinandergereiht wurden, werden sie nun Lauflängenkodiert. Dabei werden allerdings nur die Nullwerte zusammengefasst. Bei der Lauflängenkodierung werden mehrmals vorkommende Werte nur einmal zusammen mit einem Zähler kodiert. Da allerdings auch der Zähler Speicherplatz beansprucht, werden Werte mit kleinen Zählern (bis ca. 3) garnicht kodiert. Deshalb beschränkt sich die Kodierung lediglich auf die Nullen der Reihe. Die RLE bildet ein separates, und auch komplexes Thema, dass hier nicht genauer besprochen werden soll (wie die meisten anderen Themen auch). Die Entropie-KodierungIm letzten Schritt werden die Bilddaten nach der statischen Huffmann-Kodierung kodiert. Da dieses Thema allerdings so komplex und, was noch wichtiger ist, so standardisiert ist, wird es hier nur erwähnt und nicht besprochen. ↑ Nach obenDie Enkodierung in der PraxisUm nun ein Video umwandeln zu können, braucht man natürlich Software. Folgende Liste guter und kostenloser Software schlage ich vor: Beim Programm TMpgENC ist noch anzumerken, dass MPEG2 Videos nur auf 30 Tage befristet sind.
Diese Anleitungen enthalten auch Hinweise wie das extrahieren von Audiospuren etc. |
|||||||||||||
| ©2005 by Antonio Zangaro |